Skip to content
Infer() Summit 2026:
Hear from the engineers shaping the future of AI inference ->
Docs
Pricing
Blog
Solutions
Game Development
Media and Entertainment
Docs
Pricing
Blog
Solutions
Game Development
Media and Entertainment
Get in Touch
AI/ML
April 29, 2026
Disaggregated Inference, Part 1: When & Where to Route
Hien Luu
Inference
June 16, 2026
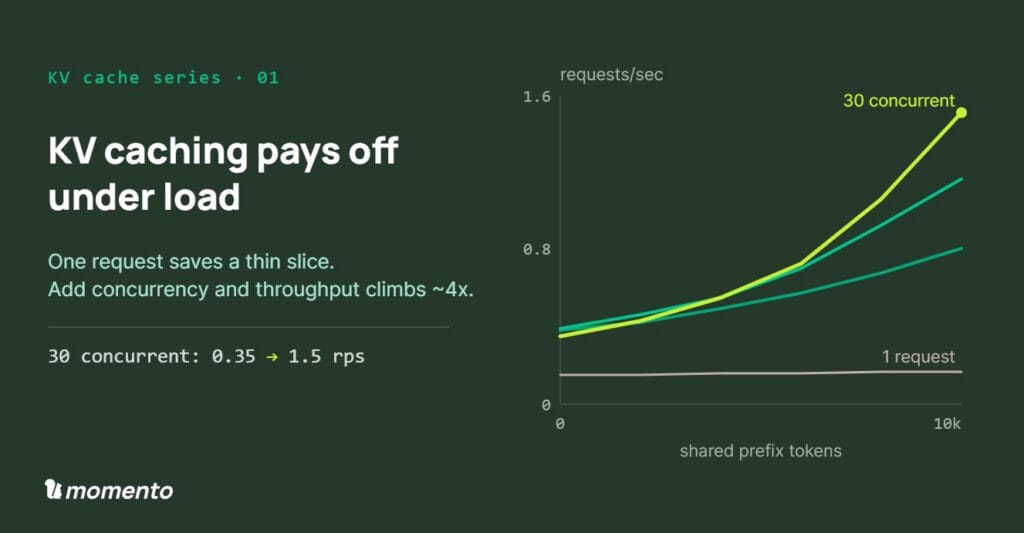
KV Caching Pays Off Under Load
Khawaja Shams
Infer Summit
Jul 7, 2026
Unlocked Conference – Seattle
May 5, 2026
T-Mobile Park, Seattle, WA
Unlocked Conference – San Jose
Jul 7, 2026
AWS re:Invent 2025
Dec 12, 2025
Las Vegas, NV
QCon SF: Real-World Technical Talks
Nov 11, 2025
Hyatt Regency, SF
Building Efficient Systems: Protosockets to Global Tables
Oct 10, 2025
Oct 2025 Meetup—Atomic Slot Migration & Modern Hash Tables
Oct 10, 2025
Transactions and Coordination in Aurora DSQL
Aug 8, 2025
IBC 2025—Amsterdam
Sep 9, 2025
RAI Amsterdam
Portland Video Tech Meetup
May 5, 2025
June 2025 Meetup—Presentations on Valkey Optimizations and Memcached
Jun 6, 2025
SURF Incubator
NABShow
Apr 4, 2025
Las Vegas, NV
We've detected you might be speaking a different language. Do you want to change to:
EN
EN
JP
Change Language
Close and do not switch language
We've detected you might be speaking a different language. Do you want to change to:
EN
EN
JP
Change Language