Skip to content
Infer() Summit 2026:
Hear from the engineers shaping the future of AI inference ->
Docs
Pricing
Blog
Solutions
Game Development
Media and Entertainment
Docs
Pricing
Blog
Solutions
Game Development
Media and Entertainment
Get in Touch
AI/ML
April 29, 2026
Disaggregated Inference, Part 1: When & Where to Route
Hien Luu
Inference
June 16, 2026
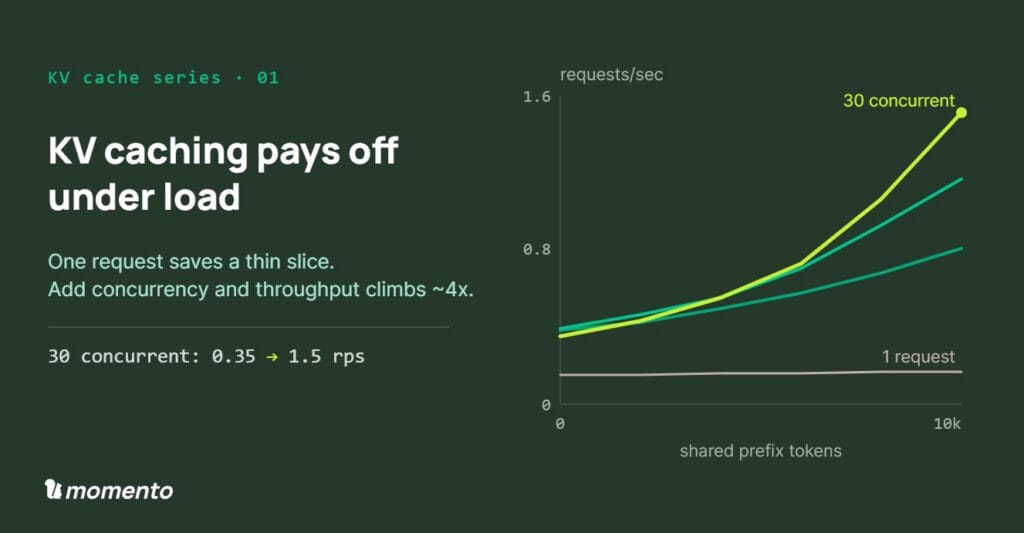
KV Caching Pays Off Under Load
Khawaja Shams
KV Caching Pays Off Under Load
Inference
Jun 16, 2026
Beyond the Goals, Three Ways Momento Scales the Football World Cup in Real Time
Media & Entertainment
Jun 03, 2026
A New Live Streaming Origin Built for Global Scale
Media & Entertainment
May 28, 2026
Introducing valkey-lab: Stop Guessing When Your Cache Hits Its Limit
Valkey
May 26, 2026
Why Snap Was Willing to Fork, and Why They Still Came Back
Caching
,
Valkey
May 21, 2026
Why Large Payloads Break Caches at Scale
Scale
May 21, 2026
Disaggregated LLM Inference, Part 3: Why Your Networking Stack May Not Be Ready
AI/ML
May 13, 2026
Disaggregated Inference,Part 2: Moving the KV Cache Without Stalling the Decode
AI/ML
May 06, 2026
The Snowflake Moment for Inference
AI/ML
May 04, 2026
Disaggregated Inference, Part 1: When & Where to Route
AI/ML
Apr 29, 2026
Prefill and Decode Want Different Chips. The Economics Finally Agree.
AI/ML
,
Performance
Apr 22, 2026
1-Bit Models Just Moved the Pareto Frontier
AI/ML
Apr 08, 2026
Your AI Remembers Everything Except the Thing You Keep Telling It
AI/ML
Mar 27, 2026
KV Cache Isn’t a Caching Problem
AI/ML
Mar 13, 2026
The Rise of the Internal Cache Platform
Caching
Mar 12, 2026
A Roadmap for KV Cache Offloading at Scale
AI/ML
Mar 09, 2026
GPUs are the most expensive resource in tech. We’re using them badly.
AI/ML
Mar 06, 2026
Stop CDN Leeching with Concurrency Tracking
Media & Entertainment
,
Security
Mar 05, 2026
What Hyperscale Caching Taught Us About GPU Utilization
AI/ML
Mar 04, 2026
Tooling is a Scaling Strategy
Scale
Mar 03, 2026
We've detected you might be speaking a different language. Do you want to change to:
EN
EN
JP
Change Language
Close and do not switch language
We've detected you might be speaking a different language. Do you want to change to:
EN
EN
JP
Change Language