
ベクトルインデックスのパワーを活用し、高速検索を実現。

情報の飛躍的な増加に伴い、検索システムの構築は現代のエンジニアにとって不可欠なツールとなっています。ウェブサイトに検索機能を構築するには、データのインデックスを作成し、検索するための専用インフラを構築する必要があり、敷居が高く、コストもかかります。
このシリーズでは、手間をかけずに迅速かつ強力な検索システムを構築する方法をお教えします。基本的な検索から始め、シリーズが進むにつれて追加・改良していきます。この検索に使う秘密のツールは、大規模な言語モデルとベクトル・インデックスです。
ベクトル・インデックスは、データをベクトル形式で保存・管理するための強力なツールです。各ベクトルの方向は、データの本質的な属性や特徴を符号化します。これらのデータストアは、画像の逆引き検索やAIチャットボットの強化など、高度な機能を実現する上で重要な役割を果たします。
ベクターインデックスのコンセプトは複雑で敷居が高く見えるかもしれませんが、Momentoはそのプロセスを簡素化しました。驚くことに、わずか数行のコードで、ベクターインデックスは、あなたが依存している検索機能の多くをシームレスに置き換えることができます。このエキサイティングなテクノロジーをさらに掘り下げてみましょう。
アーキテクチャ
テストアプリのために、タイトルと説明文から映画を検索できるシンプルな映画カタログ・サービスを構築します(データセットはここから入手しました)。最終的には、以下のようなアーキテクチャになります:
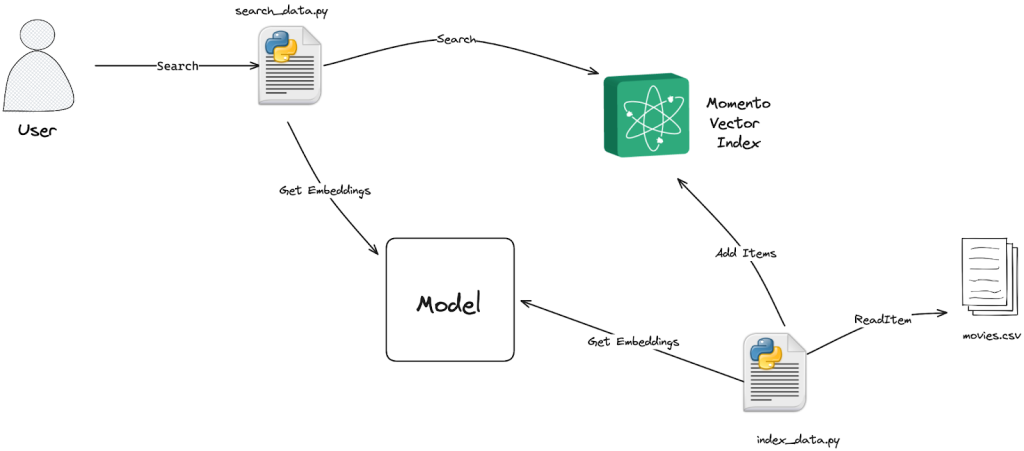
テキストからベクトルを作成
このチュートリアルでは、入力テキストから埋め込み(ベクトル)を生成する汎用モデルであるSentence Transformers all-MiniLM-L6-v2モデルを使用します。私たちは、この要求を行うための簡単なユーティリティ関数get_embeddingを書こうとしています。
from sentence_transformers import SentenceTransformer, util
def get_embedding(i):
model = SentenceTransformer("all-MiniLM-L6-v2")
model.max_seq_length = 256
return model.encode(i, normalize_embeddings = True)
)
データをインデックスに取り込む
次に、movies.csvデータファイルをスキャンして、各アイテムのエンベッディングを取得し、Momento Vector Indexに挿入してみましょう。そのためのコードは次のようになります。
import pandas as pd
from examples.moviesearch.util import get_embedding
from momento import(
CredentialProvider,
PreviewVectorIndexClient,
VectorIndexConfigurations,
)
from momento.requests.vector_index import Item
from momento.responses.vector_index import(
UpsertItemBatch,
)
# Instantiate Momento Vector Client
client = PreviewVectorIndexClient(
VectorIndexConfigurations.Default.latest(),
CredentialProvider.from_environment_variable("AUTH_TOKEN")
)
# Read CSV data of movies into dataframe
df = pd.read_csv('~/Downloads/movies_metadata.csv', low_memory = False).head(n = 100)
# Get embeddings for each movie from open AI
items_to_be_indexed = []
for index, row in df.iterrows():
items_to_be_indexed.append(Item(
vector = get_embedding(str(row['title']) + " " + str(row['overview'])),
id = str(index),
metadata = {
'title': row['title']
}
))
# Delete and recreate index on momento
client.delete_index(index_name = 'movies')
client.create_index(
index_name = 'movies',
# base num of dimensions off first vector we want to insert
num_dimensions = len(items_to_be_indexed[0].vector)
)
# add items into momento
rsp = mvi_client.upsert_item_batch("movies", items_to_be_indexed)
try:
assert isinstance(rsp, UpsertItemBatch.Success)
except:
print(add_rsp)
検索データ
データをインデックスに読み込んだので、プレーン・テキスト・クエリーで簡単に検索できます。例えば、「犬」が出てくる映画を検索してみましょう。
from examples.moviesearch.util import get_embedding
from momento import (
CredentialProvider,
PreviewVectorIndexClient,
VectorIndexConfigurations,
)
from momento.responses.vector_index import Search
client = PreviewVectorIndexClient(
VectorIndexConfigurations.Default.latest(),
CredentialProvider.from_environment_variable("AUTH_TOKEN")
)
rsp = client.search(
index_name='movies',
query_vector=get_embedding("dog"),
top_k=10,
metadata_fields=['title']
)
assert isinstance(rsp, Search.Success)
for result in rsp.hits:
print(
f"{result.metadata['title']}: {round(result.distance, 3)}"
)
これを実行すると、次のような出力が得られます:
Babe: 0.784
Balto: 0.779
結論と次のステップ
これだけです!わずか数分で、あなたのスタックに基本的な検索機能が追加されました!
次回のブログでは、以下の方法をご紹介します:
・検索の質を測る
・より正確な結果を得るために、埋め込み関数への入力データの渡し方を調整する。
・映画のインデックスに追加データを追加する
・複数のインデックスを使用し、特定のフィールドに異なる重みを割り当てる。
・検索にビジネスロジックを注入する!
・独自のモデルを持ち込む
・スケーリングに役立つキャッシュを追加する。
Momento Vector Indexはベータ版です!今日からインデックス作成を開始しましょう。