Disaggregated LLM Inference, Part 3: Why Your Networking Stack May Not Be Ready
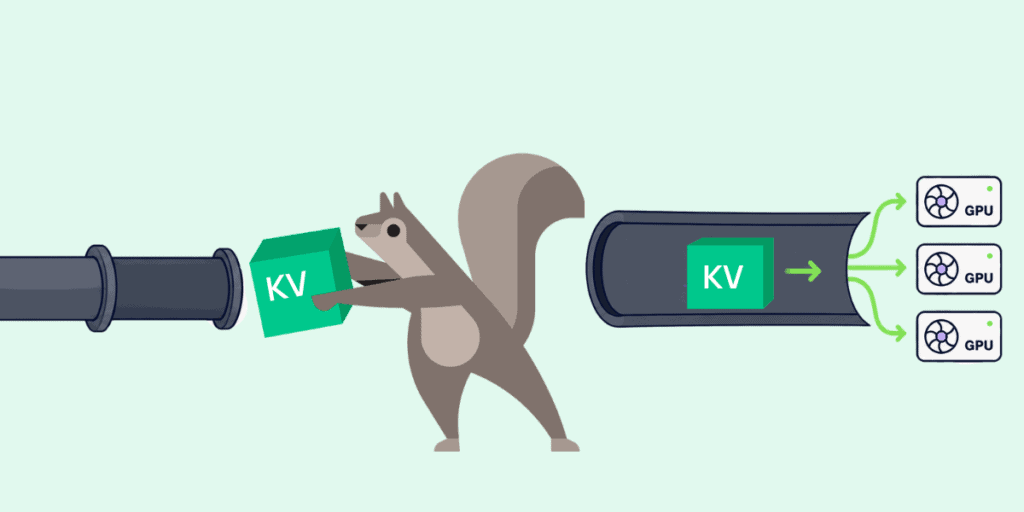
Disaggregated LLM inference shifts the bottleneck from GPUs to the networking stack, where cache movement and data-plane efficiency now define performance at scale.
Disaggregated Inference,Part 2: Moving the KV Cache Without Stalling the Decode
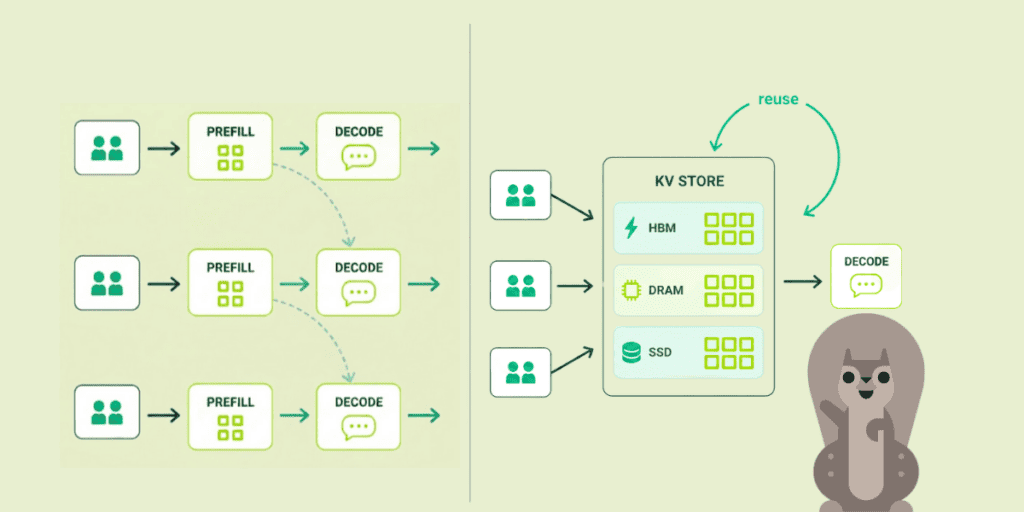
The real gains in LLM inference don’t come from faster GPUs, but from orchestrating KV Cache movement so work is reused instead of repeated
The Snowflake Moment for Inference
A decade ago, Snowflake demonstrated the value of separating storage from compute. It’s hard to overstate how much that single architectural choice transformed data warehousing and analytics. Decoupling systems with fundamentally different behaviors allows them to scale independently on dedicated hardware, with distinct optimizations and separate costs. That pattern wasn’t unique to data warehousing. Since […]
Disaggregated Inference, Part 1: When & Where to Route
If your GPUs are “busy” but users still see lag, the problem isn’t capacity, it’s mixing prefill and decode on the same hardware.
Prefill and Decode Want Different Chips. The Economics Finally Agree.

Splitting inference across specialized hardware can cut costs dramatically, but making it work in production depends on better scheduling and data movement.
1-Bit Models Just Moved the Pareto Frontier
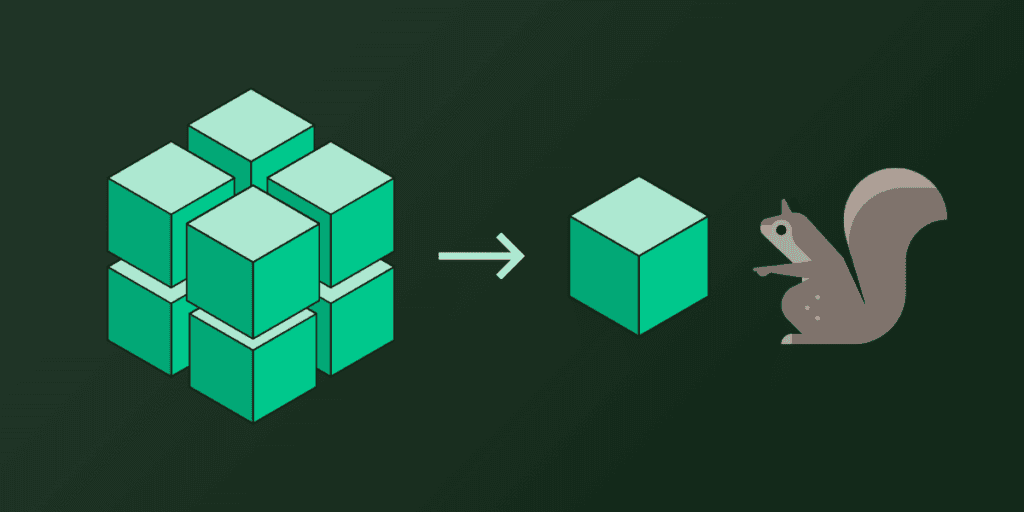
A new 1-bit compression approach preserves model quality while dramatically reducing memory, latency, and energy for real-world inference.
Your AI Remembers Everything Except the Thing You Keep Telling It

Every AI agent starts with a system prompt. It might be a few sentences instructing the model to respond formally, or thousands of tokens of business context, product knowledge, and behavioral guardrails. Either way, every single request your application sends includes it. Word for word, token for token, every time. And every single time, the […]
KV Cache Isn’t a Caching Problem

The industry is debating where to store KV cache. That’s the wrong debate. You step away from a conversation with your AI assistant to grab a coffee. Ten minutes later you come back, ask a follow-up question, and notice it feels slower. That spinner runs a little longer than usual. The model seems to […]
A Roadmap for KV Cache Offloading at Scale
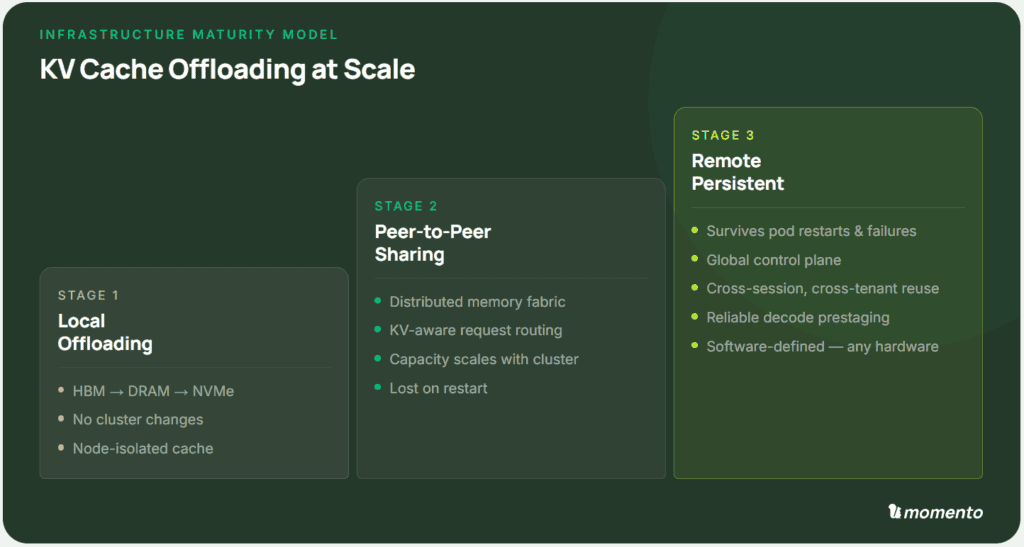
Today, the sheer size of the KV cache presents an enormous problem for inference at scale. GPU HBM can’t scale vertically fast enough to match the explosive growth of the KV cache, driven by longer context windows, multi-turn sessions, and agentic workloads that treat inference state as persistent rather than ephemeral. The solution, now adopted […]
GPUs are the most expensive resource in tech. We’re using them badly.

GPUs cost $2-4/hour and AI fleets run hundreds of them. With sticky session routing, you’re probably wasting half of them. Every time you send a message to an AI assistant, somewhere a GPU wakes up and gets to work. GPUs weren’t built for this. They were designed to render video game frames — massively […]
What Hyperscale Caching Taught Us About GPU Utilization
Lessons from ultra-low-latency systems are reshaping LLM inference. There’s a quiet revolution happening at the intersection of two worlds that don’t often talk to each other: high-performance caching systems and large language model inference. At Momento, we’ve built the world’s fastest hyperscale cache, engineered to respond in under 100 microseconds. Now, we’re translating decades of […]
Reduce TTFT by >50% with LMCache + Momento

This post explores the performance gains from offloading the KV cache to remote storage (Valkey + S3) with LMCache and Momento Accelerator. In this series, we investigate the performance gains for large-scale inference clusters with distributed KV caching, optimized routing, cluster orchestration, and other techniques. This post focuses on offloading the KV cache to remote […]